While learning Japanese, I was looking for some tool, which would help me training Kanji and vocabulary/idioms at the same time. Although there are plenty of free Kanjitrainers available, I didn't find one which would easily support the way I am learning Japanese, so I wrote my own. The result is kanren (an abbreviation for 漢字 and 練習). kanren is designed by observing the following points:
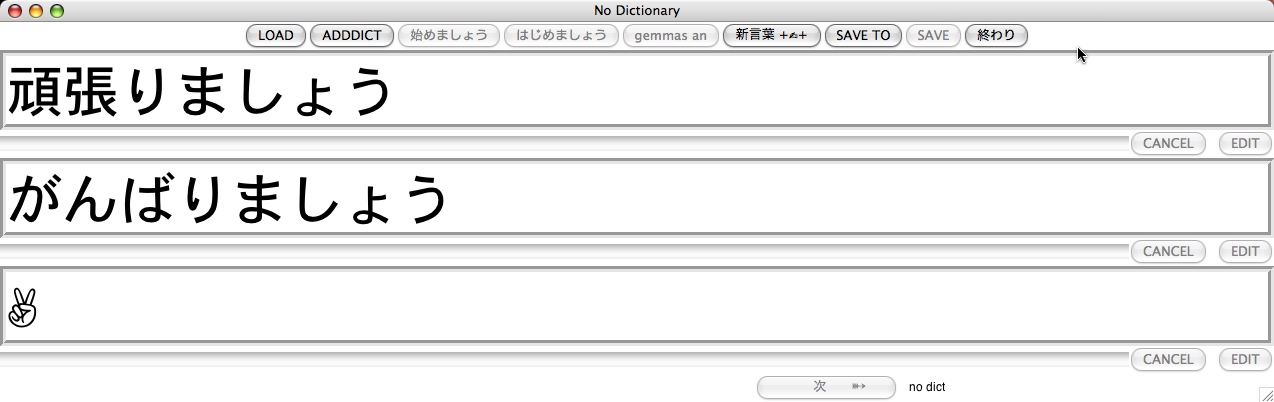
When working with kanren, the learner first defines his or her dictionary, each entry being a triple of idioms - one in the learner's language, one in Hiragana and Katakana, and (optionally) one in Kanji. Once the dictionary has a sufficient amount of entries, training may start. For the training process, the learner specifies, which component of the triple is being prompted first. For example, I usually start with being prompted in my own language, but for Kanji-Reading-Exercises, I would of course start with the Kanji representation being prompted first.
After being prompted, the user is supposed to say aloud the term in Japanese, and click a button for getting the spelling in Kana as feedback. Finally, the third form of the idiom needs to be checked. If a Kanji is asked for, the user needs to imagine clearly the strokeorder, writing mentally the Kanji. The user finally gets all three idioms displayed. At this time, s/he decides whether the problem should be considered to be solved correctly or not, and gets the next idiom prompted.
Note that there is no "multiple choice" question involved, as in many other Kanji training programs!
kanren keeps a record of the correct and incorrect responses and tries to balance the challenges over time, so that idioms which get usually correct responses, are in the end prompted less frequently than those where an incorrect answer is frequently given.
kanren is implemented in the programming language Python, and you need to have Python installed on your system. Unless you happen to use Windows, chances are good that you already have a suitable Python on your computer. To check this, open a command line shell and enter
python -V
This should output the version number of the Python in your PATH, if there is any. Otherwise you need to download and install Python first.
Note:If downloading Python, you need to select for installation a Python version which contains Tkinter. Most Pythons are built with this extension, but sometimes you can choose to dowload a Python with or without Tkinter.
Special notes for Windows users:
kanren has been tested on the following platforms:
python kanren.py --help
This should output a short description of the command line parameters. If this works, enter
python kanren.py
A window should open, similar to the one on top of this page. If this is not the case, in particular if you get an error message related to tk or tkinter, it is likely that your Python has either not been built with tkinter support, or that the Tk libraries are missing on your system. In this case, install a suitable Python version and try again.
To add idioms to a dictionary, and this includes the initial empty dictionary, click the
button  . This allows you to repeatedly enter idioms.
Leave the Kanji field empty, if you don't want to use Kanji for this idiom.
. This allows you to repeatedly enter idioms.
Leave the Kanji field empty, if you don't want to use Kanji for this idiom.
Note for Mac Users: The current ports of Tk (which is used internally by Python/tkinter) for the Mac seem to suffer from a bug in the Tk library, which makes it impossible to use the Kotoeri input method for Japanese text. See here for details. If you face this problem, the only workaround is to type the Japanese idioms in a text editor and copy and paste them into the kanren entry fields.
If you add words to an empty (unnamed) dictionary, you need to save the dictionary to a text file, before you can actually use it. You need a certain (configurable) minimum number (default: 3) of idioms in the dictionary, before you can acutally use it.
Using the button, you replace the current (possibly empty/unsaved) dictionary by a new one. Dictionaries are stored in text files using UTF-8 encoding. While the format of the dictionaries is specially tailored to kanren, it still is plain text, and this means that you can also create a dictionary with the help of a text editor. I consider this the most convenient input method for dictionaries containing a few dozens of entries.
The file format for a dictionary file is as follows:
KANREN01 and identifies the
version of the dictionary format.:)-) if there is no Kanji representation for this idiom.
/).
#). Note that comments are not preserved
upon saving a dictionary. They are simply ignored when reading it. If you prefer using the
text editor to create a large, initial dictionary, and use comments, make sure that in the
course of your training, you are using a new name when saving the file.
Clicking the button will prompt you for a file name, where the dictionary is written to. This is used if you start with an empty dictionary and add idioms interactively, or if you want to create a snapshot of the current dictionary state for later use.
Clicking the button will just save (i.e. export) the dictionary to the current name. The saved data contains not only the idioms, but also your achievements, and is used for the next training to determine the frequency of the idioms being asked. Therefore, even if you did not add or edit idioms during the training, it is advisable to save the dictionary from time to time.
Note also that there is no automatic saving of the dictionary at the end of a training. You need to decide whether the training was to be taken seriously (and your achievements should be recorded), or a mere playing around with the program. In the latter case, you will likely not want to save the changes.
Note: The current (beta-)version of kanren offers no recovery from a failed merge yet. If the merged dictionary encounters an idiom which is already present in the current dictionary, the merge aborts with an error message and the dictionary is left in an inconsistent state. This will be fixed in a later version. The current workaround requires, that you SAVE the dictionary first, then perform the MERGE, and if the merge fails, LOAD the old dictionary again.
To start the training, click one of the buttons
,
or , depending on whether you want to be queried
the Kanji representation, the Kana representation or the representation of the idiom in your
language. After making up your mind about the other two representations of the idiom, each
click on the button  displays the next
representation. After the last representation, you need to decide whether you consider the
challenge solved or not. kanren uses this information to
calculate the probabilities for the individual challenge.
displays the next
representation. After the last representation, you need to decide whether you consider the
challenge solved or not. kanren uses this information to
calculate the probabilities for the individual challenge.
If you find a typo in an idiom while doing the training, you can correct it on the fly by clicking the button. For editing, the restrictions listed in Adding Idioms Interactively apply in the same way.
If you finished the training, it is advisable that you save the dictionary. Doing this, a record of your responses is saved in abriged way, and affects the sequence of challenge in the next training. This saving of the current state is NOT done automatically, because you might have wanted to play around with the system, not focusing on learning. If you, however, have editied an idiom without saving, you will be reminded that your changes will be lost if you don't save.
If you invoke kanren with the
--load parameter, i.e.
python kanren.py --load=DICTFILE
where DICTFILE is the name of a file containing the dictionary, this dictionary
is loaded automatically on program start. This comes handy if you always work with the same
dictionary and want to create a wrapper script, which automatically supplies the name of
the dictionary.